数据分析
数据分析帮助你在数据处理的基础上分析你的数据。数据分析提供各种算法和模型,用于经济学、医学、社会科学和机器学习等。
本章将告诉你如何用LCDA进行数据分析,以及我们提供的所有算法的相关信息。
点击上方导航栏中的
Data Analysis进入数据分析页面。登录后,点击右上角的
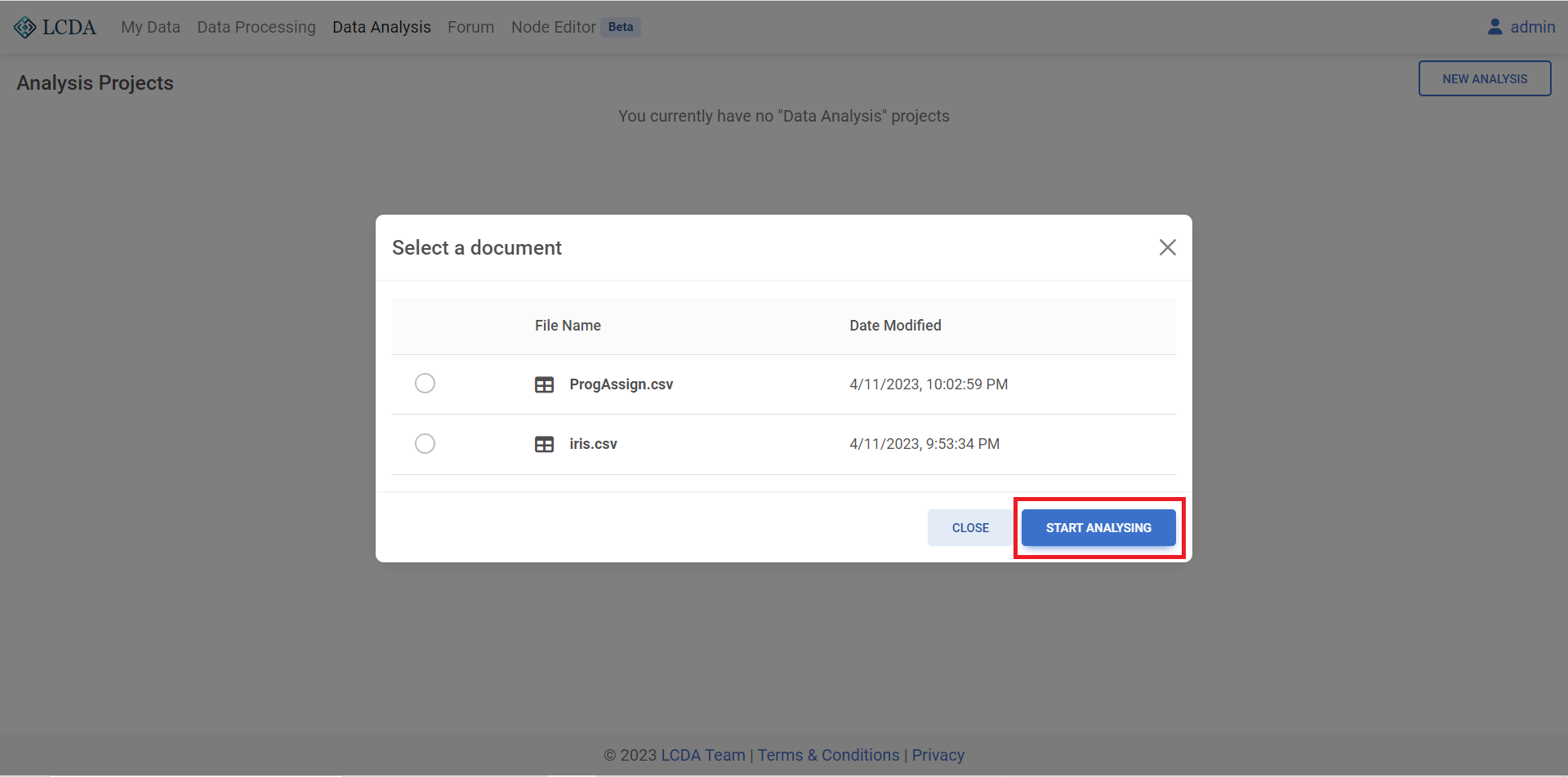
NEW ANALYSIS,这里我们选择数据集,点击START ANALYSING开始对数据进行分析。
项目页面首先会展示该项目的分析结果
Analysis results和算法选择区域Choose algorithm。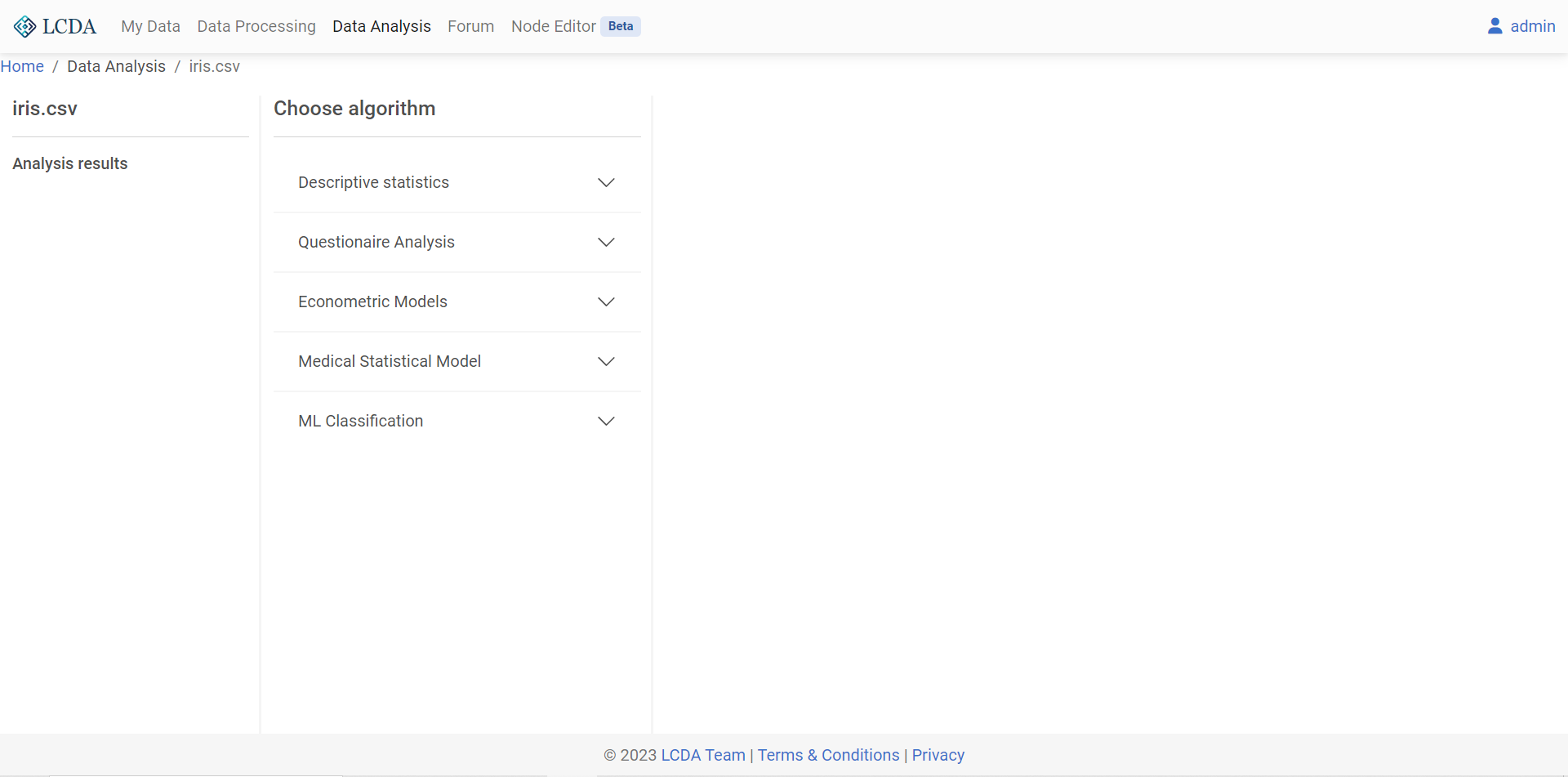
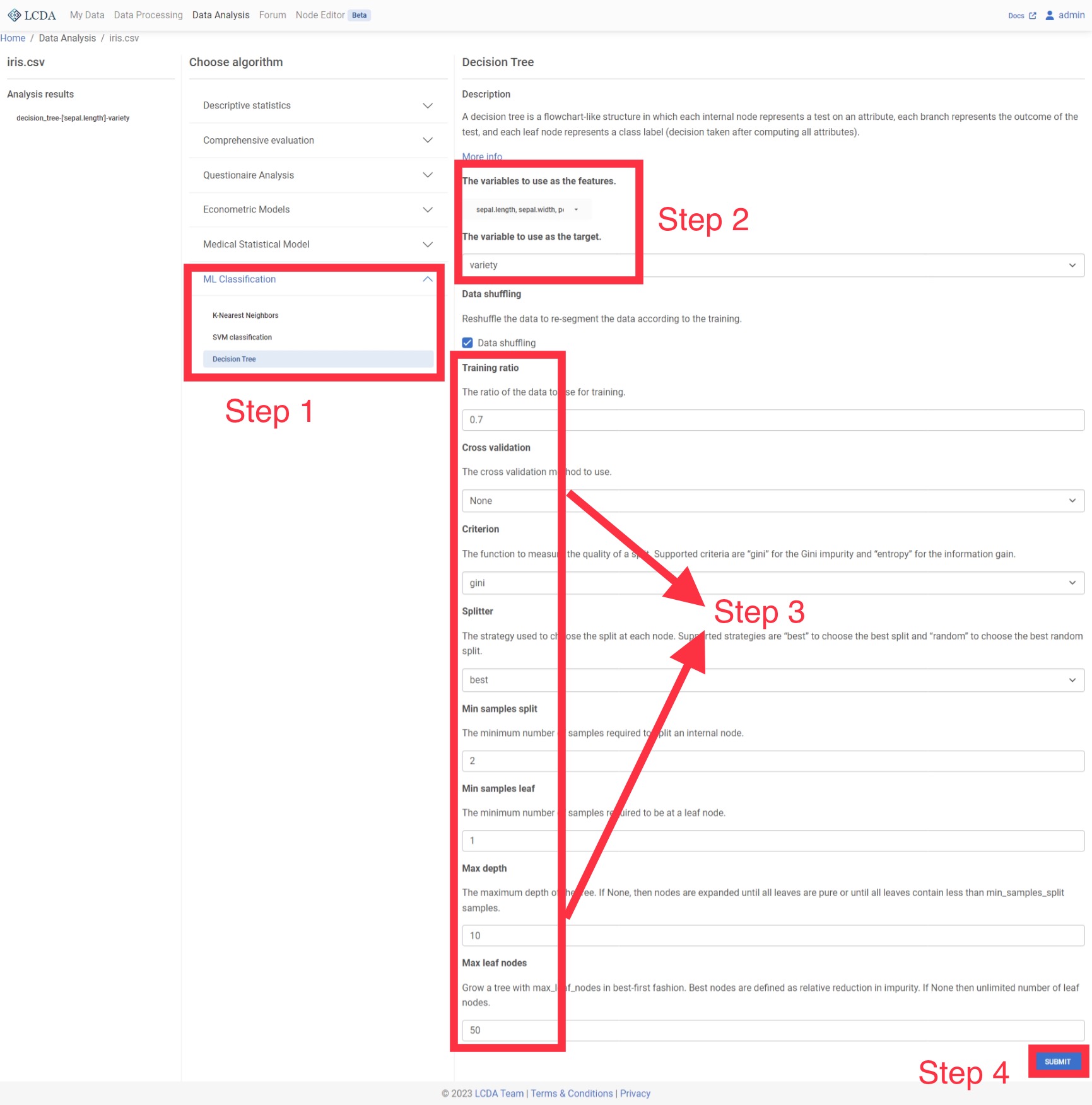
在算法选择区域,数据分析算法和模型被分为几个大类。这里我们将对鸢尾花数据集应用 KNN分类算法,因此我们点击
ML Classification,在展开项中选择K-Nearest Neighbors。右侧将会显示算法的介绍,可选参数及相应描述。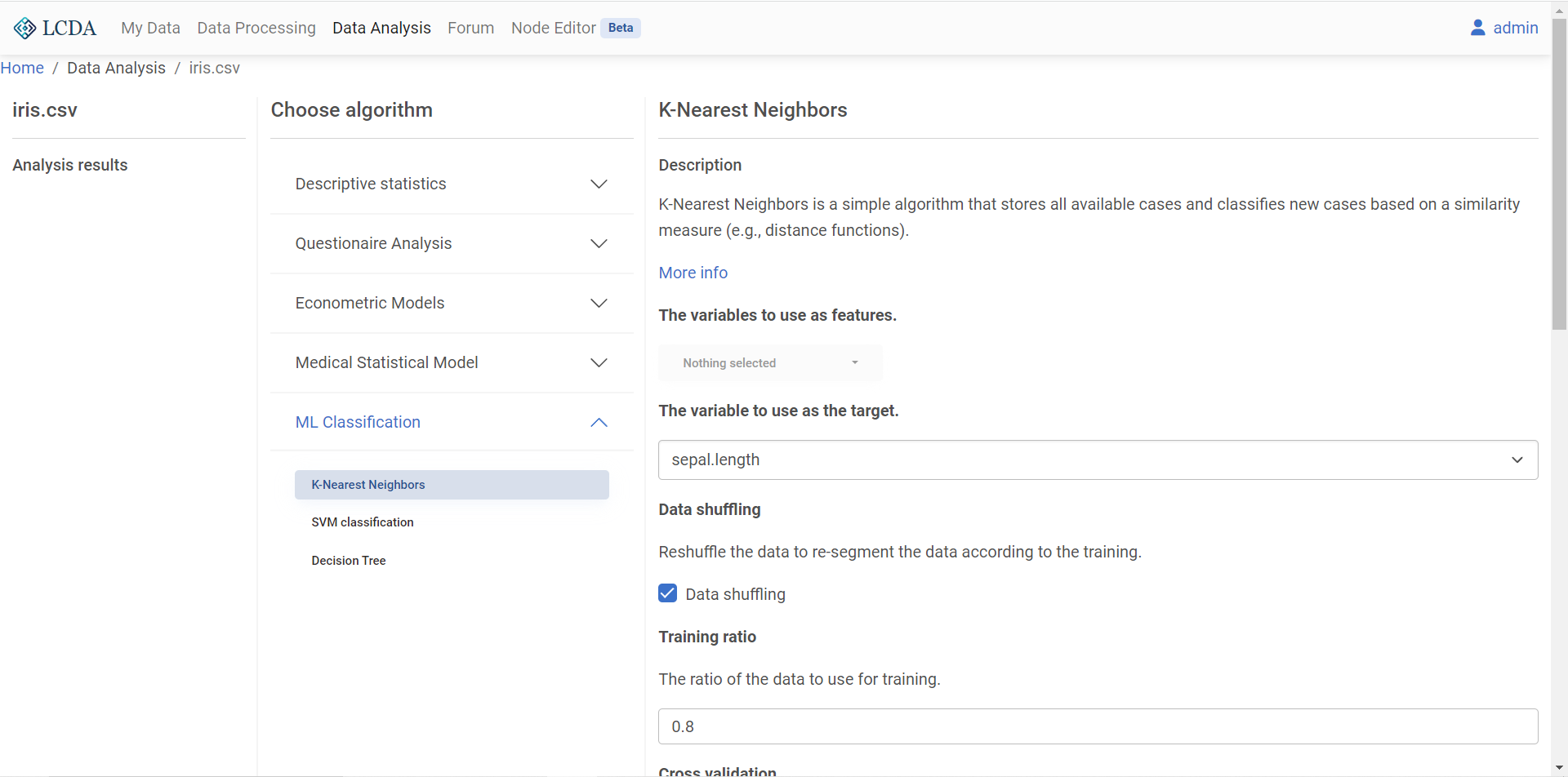 配置好参数后,在页面末尾的右下角点击
配置好参数后,在页面末尾的右下角点击 SUBMIT提交算法和参数。提交算法后,在左侧的分析结果
Analysis results中能够看到刚刚运行的算法的分析报告。点击报告,即可在右侧查看。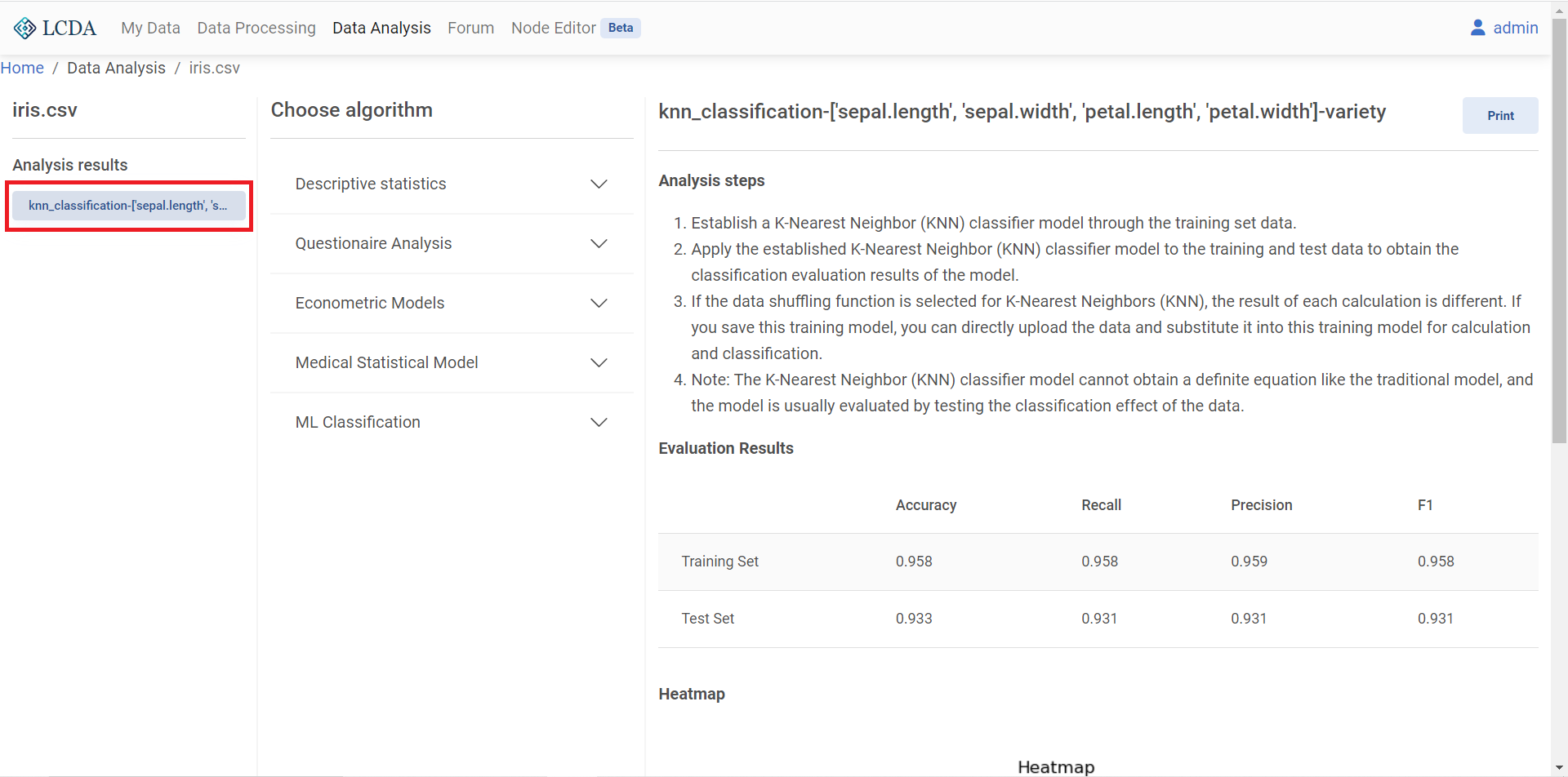
报告右上角的
Print按钮提供了报告的全屏视图和下载。
描述性分析
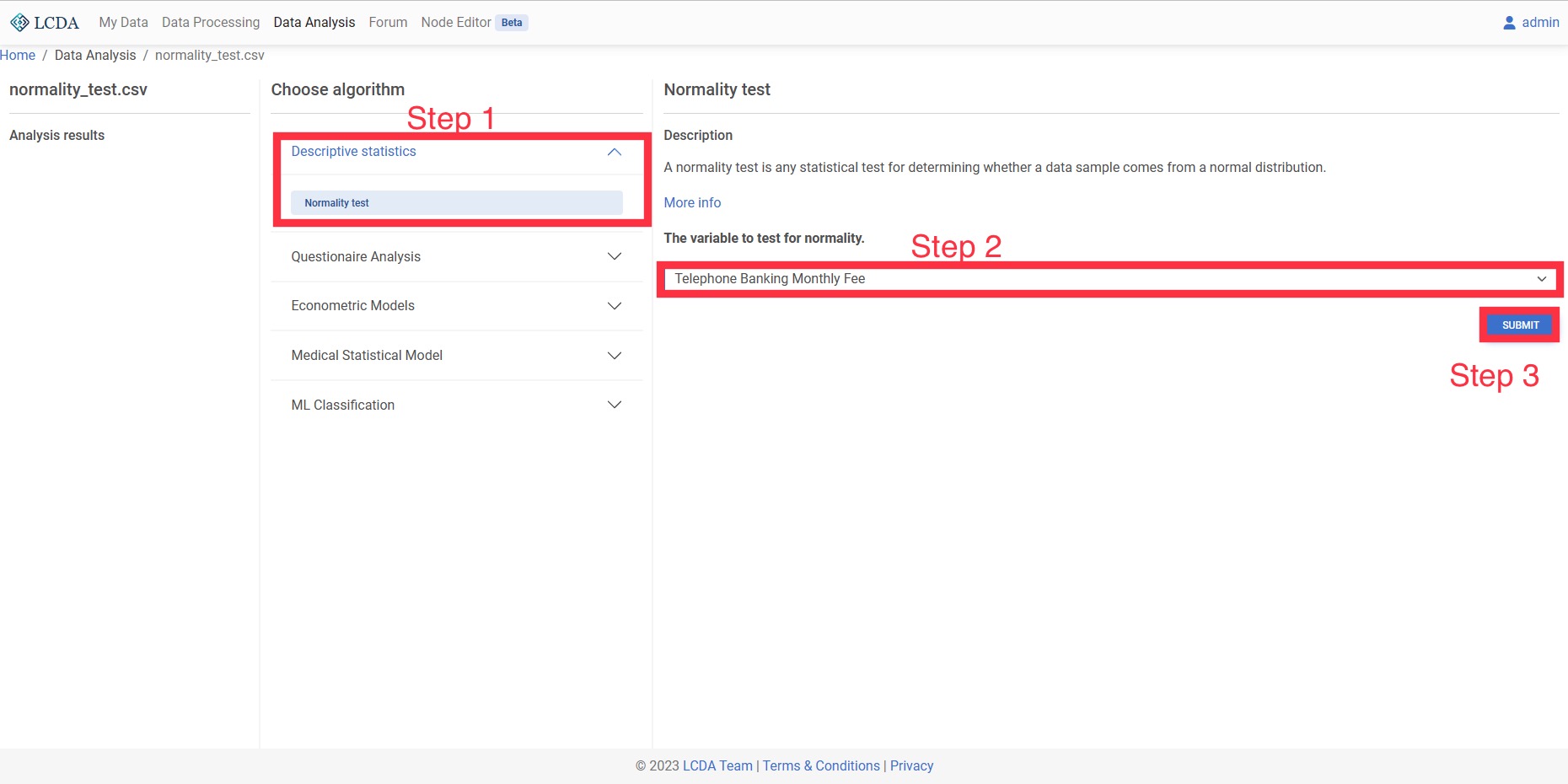
正态性分析
正态性检验用于检验数据是否满足正态分布,一些算法需要数据满足正态分布(如单样本 t 检验,独立样本 t 检验等)。
输入和输出
- 输入:一个或多个定量变量(如 30 名员工这个月的工资)。
- 输出:模型检验的结果,数据满足/不满足正态分布。
案例操作
综合评价
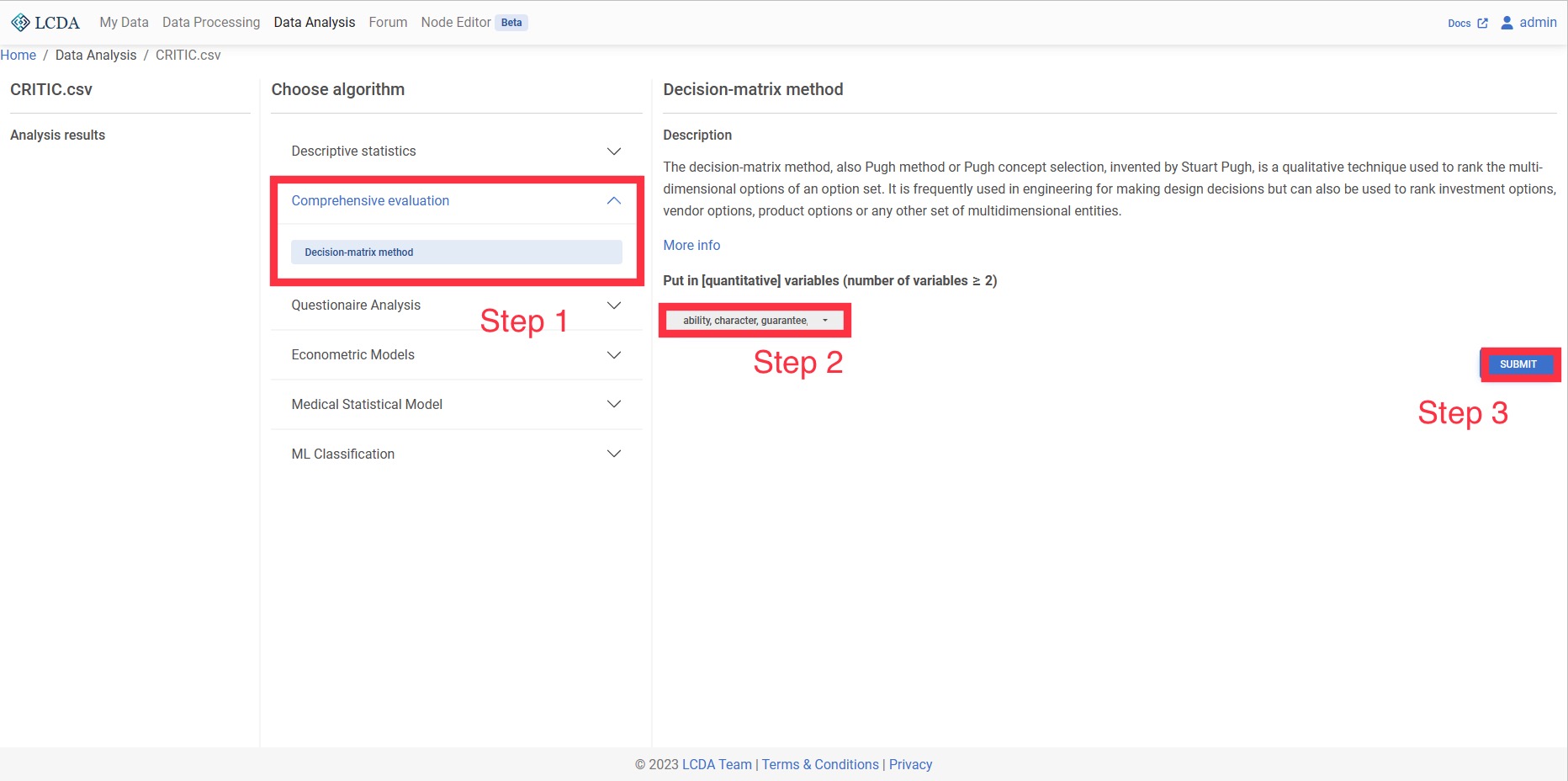
CRITIC权重法
CRITIC权重法是一种客观赋权法。其思想在于用两项指标,分别是对比强度和冲突性指标。对比强度使用标准差进行表示,如果数据标准差越大说明波动越大,权重会越高;冲突性使用相关系数进行表示,如果指标之间的相关系数值越大,说明冲突性越小,那么其权重也就越低。对于多指标多对象的综合评价问题,CRITIC法去消除一些相关性较强的指标的影响,减少指标之间信息上的重叠,更有利于得到可信的评价结果。
输入和输出
-输入:至少两项或以上的定量变量(可以做正、负向处理,但是不要做标准化)。
-输出:输入定量变量对应的权重值。
案例操作
问卷分析
信度分析
信度分析主要用来考察问卷中量表所测结果的稳定性以及一致性,即用于检验问卷中量表样本是否可靠可信。量表题型就是问题的选项,是分陈述等级进行设置的。比如我们对手机的喜爱从非常喜欢到不喜欢这个程度的变化。在量表里面最出名的就是李克特 5 级量表,在这种量表的选项里面主要是分为'非常同意'、'同意'、'不一定'、'不同意'、'非常不同意'五种回答,分别记为 5、4、3、2、1。
输入和输出
- 输入:至少两项或以上的定量变量或有序的定类变量,一般要求数据为量表数据。
- 输出:收集问卷量表的信度是否可靠。
案例操作

计量经济模型
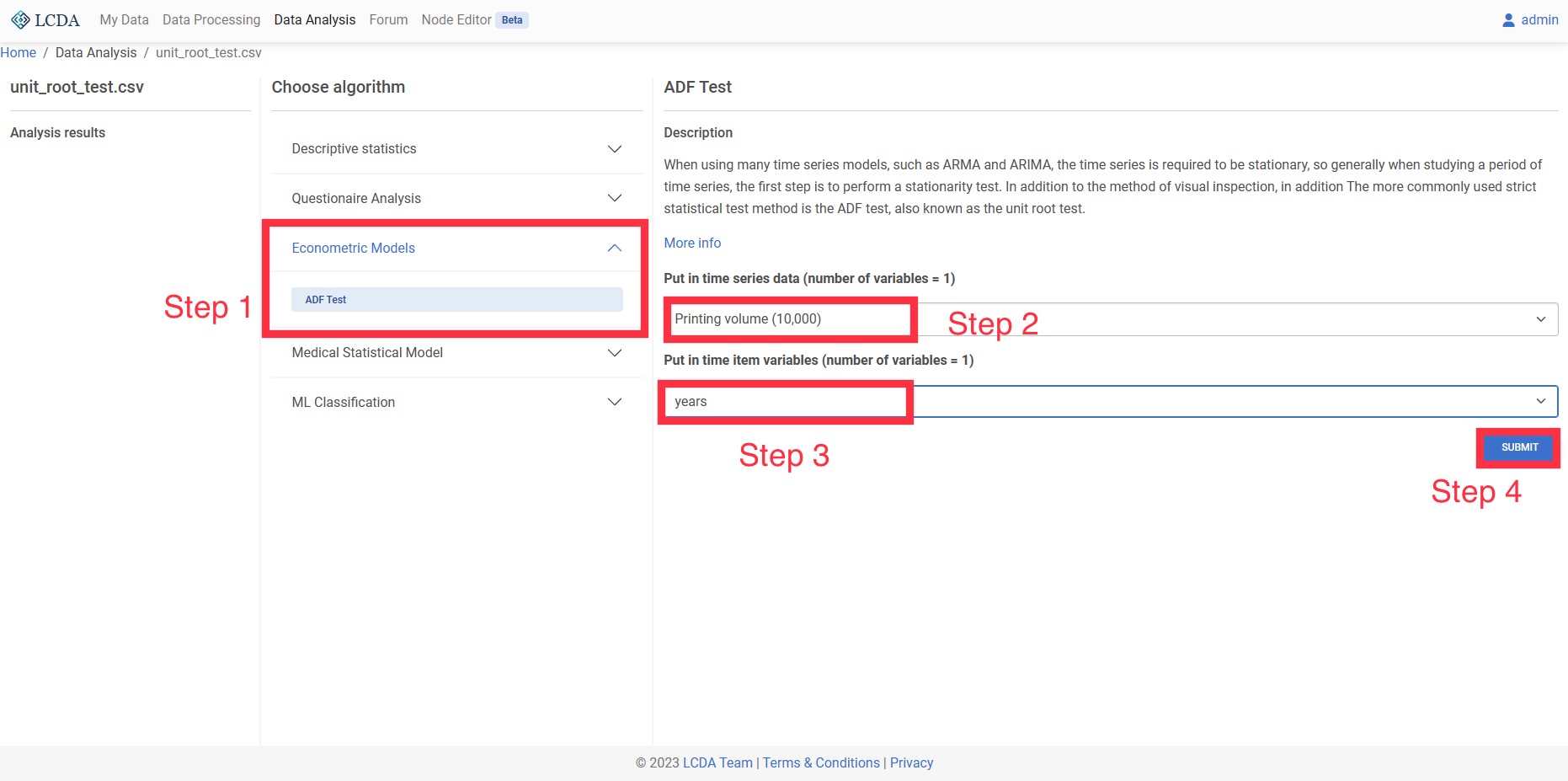
单位根检验(ADF)
在使用很多时间序列模型的时候,如 ARMA、ARIMA,都会要求时间序列是平稳的,所以一般在研究一段时间序列的时候,第一步都需要进行平稳性检验,除了用肉眼检测的方法,另外比较常用的严格的统计检验方法就是 ADF 检验,也叫做单位根检验。单位根检验是指检验序列中是否存在单位根,因为存在单位根就是非平稳时间序列了。
输入和输出
- 输入:1个时间序列数据定量变量
- 输出:序列数据在几阶差分时达到平稳
案例操作
医学统计模型
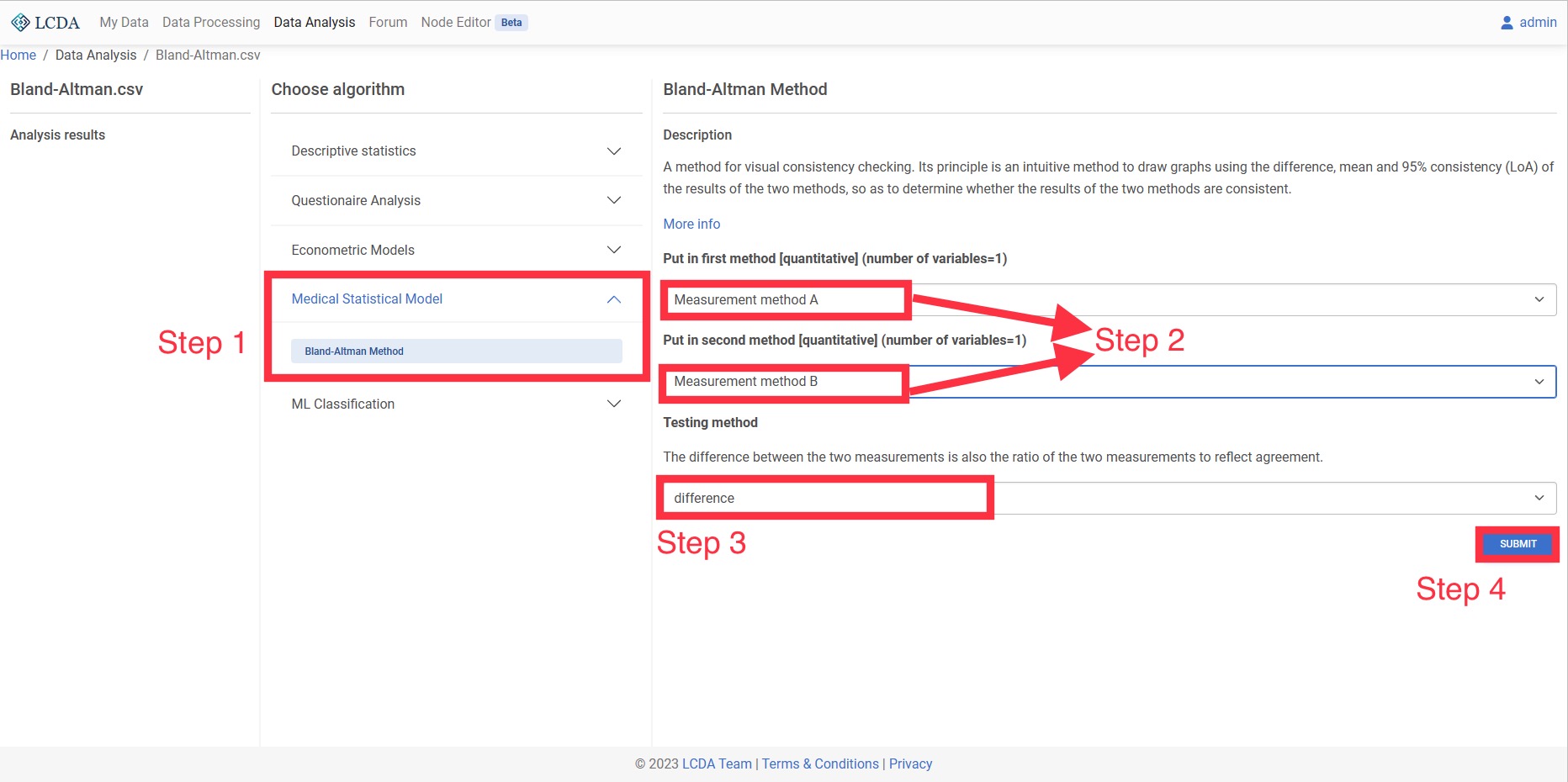
Bland-Altman法
Bland-Altman 法是一种可视化进行一致性检验的方法。其原理是一种用 2 种方法结果的差值、均值及 95%一致性(LoA)绘制图形直观的方法,从而得出 2 种方法结果是否具有一致性。
输入和输出
- 输入:代表两种方法的两个定量变量。
- 输出:Bland-Altman 图以及方法是否具有一致性。
案例操作
机器学习分类
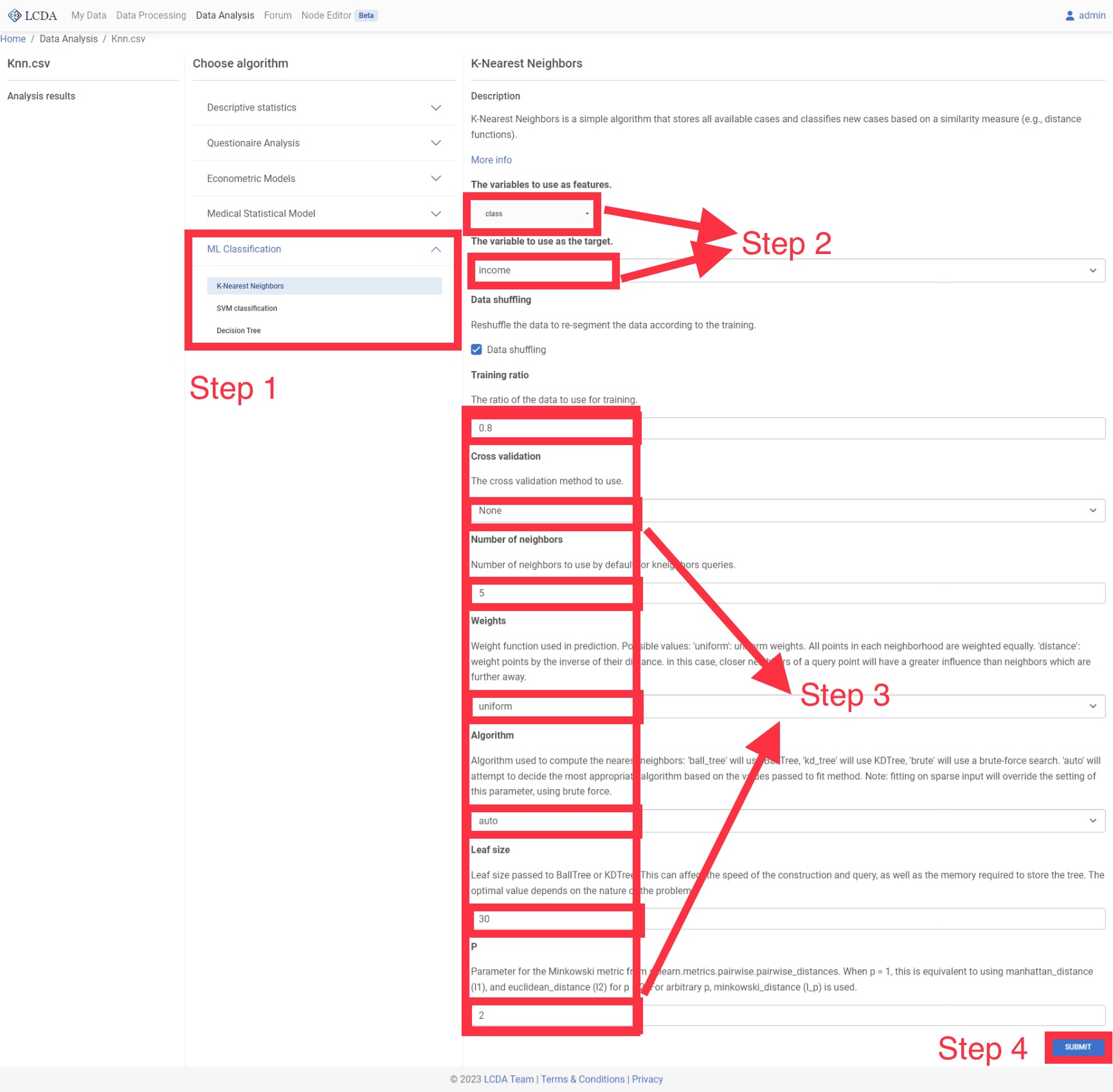
K近邻
K近邻(KNN)分类器是有监督学习中普遍使用的分类器之一,将观察值的分类判定为离它最近的k个观察值中所占比例最大的分类。
输入和输出
- 输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
- 输出:模型的分类结果和模型分类的评价效果。
案例操作
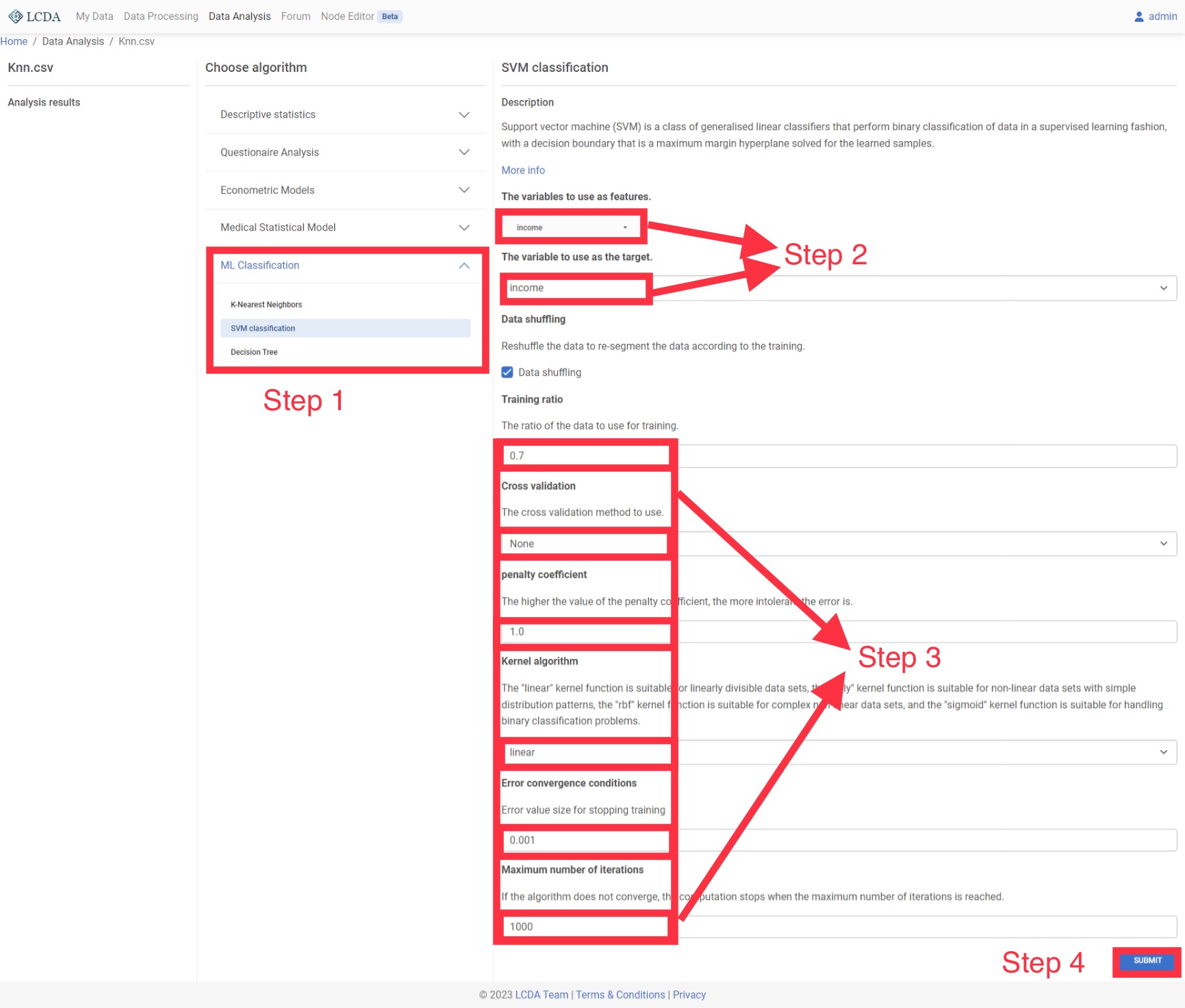
SVM
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
输入和输出
- 输入:自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
- 输出:模型的分类结果和模型分类的评价效果。
案例操作
决策树
决策树是一个类似流程图的结构,其中每个内部节点代表对一个属性的判定,每个分支代表判定的结果,每个叶子节点代表一个类别标签(在计算所有属性后做出的决定)
输入和输出
- 输入: 自变量 X 为 1 个或 1 个以上的定类或定量变量,因变量 Y 为一个定类变量。
- 输出:模型的分类结果和模型分类的评价效果。
参数选项
- 数据洗牌: 是否对数据进行随机洗牌
- 训练比例: 训练数据与整个数据集的比例
- 交叉验证: 从原始样本中随机划分出的大小相等的子样本的数量。每个子样本将被保留作为测试模型的验证数据,而其余的子样本将被用作训练数据。
- 准则: 衡量分割质量的函数。支持的标准有:
- gini:用于衡量gini不纯度
- 信息熵:用于衡量Shannon信息增长。
- 分割器: 用于在每个节点选择分割的策略。支持的策略有
- 最佳:选择最佳分割
- 随机:选择最佳随机分割
- Min Samples Split: 拆分一个内部节点所需的最小样本数:
- 如果是int,那么考虑
min_samples_split作为最小数量。 - 如果是float,那么
min_samples_split是一个分数,ceil(min_samples_split * n_samples)是每个分裂的最小样本数。
- 如果是int,那么考虑
- Min Samples Leaf: 在一个叶子节点上所需的最小样本数。任何深度的分割点只有在左右两个分支中至少留下
min_samples_leaf训练样本时才会被考虑。这可能有平滑模型的效果,特别是在回归中。- 如果是int,那么考虑
min_samples_leaf作为最小数量。 - 如果是float,那么
min_samples_leaf是一个分数,ceil(min_samples_leaf * n_samples)是每个节点的最小样本数。...... 版本变更:: 0.18 增加了分数的浮点值。
- 如果是int,那么考虑
- 最大深度: 决策树的最大深度。如果没有,那么节点会被展开,直到所有的叶子都是纯的,或者直到所有的叶子都包含小于
min_samples_split的样本。 - 最大叶子结点: 用
max_leaf_nodes以最佳优先方式生长一棵树。最佳节点被定义为相对减少的不纯度。如果没有,则叶子节点的数量不限。
例子